大家好,好久不见,我是某昨。
昨天,或者说是从更久之前,在我寒假里尝试写 libass 源码阅读的时候,再或许是更久之前,在我写林业源码阅读的时候,我就在思考这个问题了。
往窄了说,是「源码阅读系列该怎么写」;往大了讲,就是「技术型博客该怎么写」。
开始
昨天的思考是这样的:
最近一直在思考源码阅读系列的行文风格应该怎么样
抛出问题-解决问题的范式是比较适合的,但很容易就会变成 抛出问题-进入问题-进入问题-进入问题-进入问题-…-stackoverflow(不是
简单来说,就是随着调用的深入,我们更难控制上层与下层代码之间的行文方式
这种写法是跟着作者本人阅读源码的思路来的,但并不一定适合所有阅读他人阅读源码的人(好像有点绕)
换而言之,这种写法其实只是对自己思考流程的记录。真正遇到想要学习的时候,这种思路下写出的所谓源码阅读博客反而会变得难以阅读,可读性有时候甚至不如原文。
我个人更倾向的方式是从一些前置知识入手,伴随着前置知识,讲解代码中调用栈较深的部分。
但这种行文方式就要求对源码本身有相对较深程度的了解,并且通常产出较慢(因为要花更多时间组织自己对代码的认识)
写了这么多流水账,真的感觉很多时候写这种东西就是浪费生命。虽然弄懂的那一刻是有所收获的,但往后再去翻看的时候并不是那么容易理解(我当时想的是什么?
这是啥啊-保存现场-跑去查资料-恢复现场-继续阅读
这个过程是间断的,不连续的。也就是说,如果你对代码的了解过少,那么大部分时间都会与你保存的现场的代码无关。纵使你这次豁然开朗了,但下次阅读时,你还需要遍历一次之前的学习路径。
我们可以从几个例子来看。
例 1:libass 源码阅读系列
例子的原文在这里:
在这个
- 定下这篇文章的范围
- 阅读并理解源码
- 将源码对应复制上来
- 加以注解
这也就是昨天我那个主题的推上批判的行文方式。这种行文
评分:-114514
例 2:TProxy
例子的原文在这里:
这篇文章从出发来看或许和上一篇是一样的,但当一篇文章足以将所有源码讲完时,事情又发生了变化。和分割成多篇的文章系列不同,单篇文章如果可以讲完,那么读者的阅读过程就是线性的。
但这种线性也是有代价的,其代价的本质和 libass 并没有区别,即重复理解成本。这种成本是对昨天思考中这句话的总结:
纵使你这次豁然开朗了,但下次阅读时,你还需要遍历一次之前的学习路径。
是了。人总是会遗忘的,当遗忘后你想重新拾起这部分记忆时,你又需要按照上次学习时的提出问题-解决问题流程从头再来一遍。我们的学习就没有什么可以称为收获的东西吗?
评分:20
例 3:kara-templater
例子的原文在这里:
这篇文章从出发来看或许和上一篇是一样的,但有一点本质的不同:这篇文章中的某些部分是面向源码的含义讲的,而不是面向源码讲的。其中决定性的区别在于你是在写代码的补充注释还是在写源码分析。
这种「分析感」在这 parse_code 部分体现地最明显:
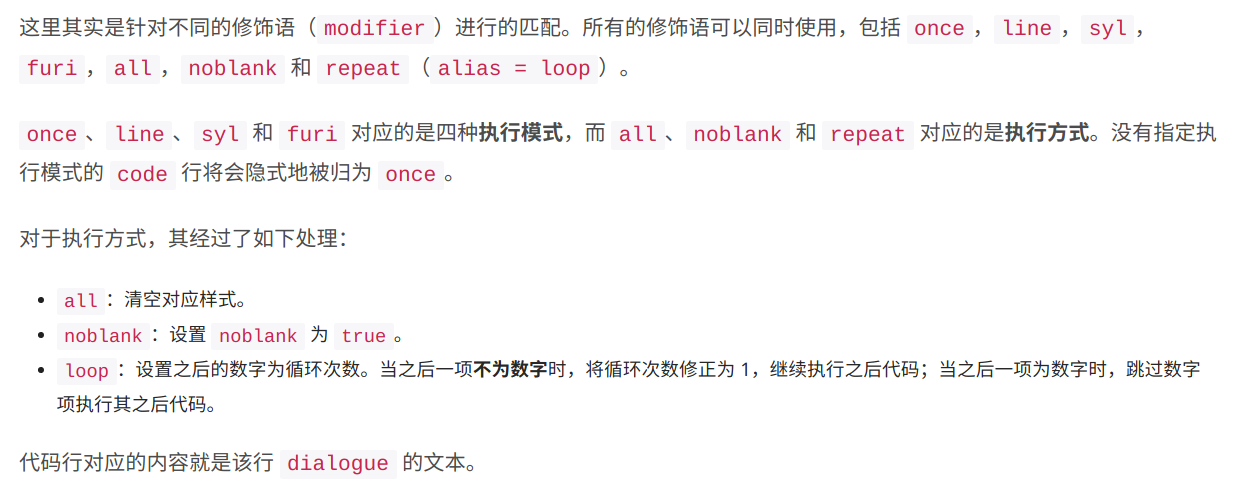
但是很遗憾,在这篇文章中,仍然有很多部分是针对源码的照本宣科。
此外,这篇文章的结构决定了它是可以各取所需的。这种各取所需性从目录就可以看出来:

当阅读中断,下次阅读时读者可以很快通过这种层次结构找到上次的中断点,而不是在一层层的函数调用中迷失自我。此外,对只想了解某一个函数实现的读者,目录也使其能够更快地找到目标。
评分:60
小结
我们不妨把一篇源码阅读文章的打分标准分为三个方面:可读性、初次理解成本和二次理解成本。
可读性
可读性体现为文章的布局结构、文笔流畅性、图文关系等。布局结构指的是多级标题、引用、代码块等页面元素之间的整体协调性;文笔流畅性指全文的文字流畅程度,包括承接、转折、文字重复度、UML 等。
其中一个我个人比较在意的点就是文字重复度,比如你在上一句话中用了「例如」,那么下一句中如果要用到同样意义的词时就应该以意义相近的词替代。试想上面的「例如」如果换成了「比如」,那是不是就和逗号后面的比如重复了呢?
初次理解成本
初次理解成本指读者第一次阅读这篇文章时,由于文章自身因素而放弃的可能性大小。放弃的可能性越大,初次理解成本越高。
初次理解成本高的原因在我目前的文章中一般是文中块与块的不协调性。块和块之间的嵌套层级过深,导致读者更难理解顶层块语境下的调用含义。我个人目前的想法是嵌套不应该超过两层,否则文章的结构就乱套了。
二次理解成本
当你出于某种原因遗忘了这篇文章中的部分内容,又想要重新拾起时,需要花费的成本称为二次理解成本。目标是将二次理解成本降低到无限接近于无,即读者在第二次阅读时能够尽可能快地回忆起自己遗忘的内容。
二次理解成本很大程度上归咎于全文的行文风格。如导览式文章的二次理解成本就比较高,因为它对问题的解决是自顶向下的,为了重新理解下层的含义需要再一次跟随导览;同理,纯文字文章的二次理解成本也比较高,因为图表很大程度上可以唤醒沉睡的记忆。
结论
我们的目标是提升可读性、降低初次和二次理解成本。这篇文章也只是单纯地描述了一下我对源码阅读类文章的评判标准,具体该如何去做还是需要根据实际情况来看。
我的计划是「重构」一遍 libass 源码阅读。这篇文章的问题太大,可读性在目前的文章中可排倒数,根本没有让人看下去的动力。在这篇文章重构完之后,我们再来看看效果如何吧。
以上~