大家好,好久不见,我是某昨。
国庆前总算是下定决心要好好整治一下现在的路由了。以笔记本为核心的代理网络虽然携带方便,但对各种设备的支持实在是算不上完全。笔记本的无线网卡限制太大(信道必须为当前连接 WiFi 的信道,并且不在限制范围内),并且因为笔记本占据了有线接口,因此其他设备就没有使用有线网络的可能了。
新的网络配置使用了一台 TPLink 的 TL-SG2008D 交换机实现单臂路由,树莓派 4B 作软路由,systemd-networkd 管理网络接口,chinadns-ng 配合 dnsmasq 解析 DNS,ipt2socks 配合 v2ray 实现透明代理,nftables 配置透明代理的规则并劫持局域网的 DNS 请求至路由器的本地 DNS 服务器。
ToC
环境分析
待接入的网络环境为 IPv4+IPv6 双栈。其中 IPv4 有 MAC 地址白名单,且需要经过 Drcom 认证才能访问公网;IPv6 为 SLAAC,自动下发一段 /64 的 IPv6 地址。IPv4 有出口限速 100M;IPv6 不限制,能够跑到宿舍交换机的上限千兆。
IPv4 这边没什么好说的,肯定是要 NAT 了,问题在 IPv6。由于下发的地址是 /64,因此简单的 SLAAC 配置就不可能了;而 Android 设备又明确表示不支持 DHCPv6。因此留给我们的只有两条路:要么透传(Passthrough),要么中继。这里我选择了 Passthrough。
配置:交换机
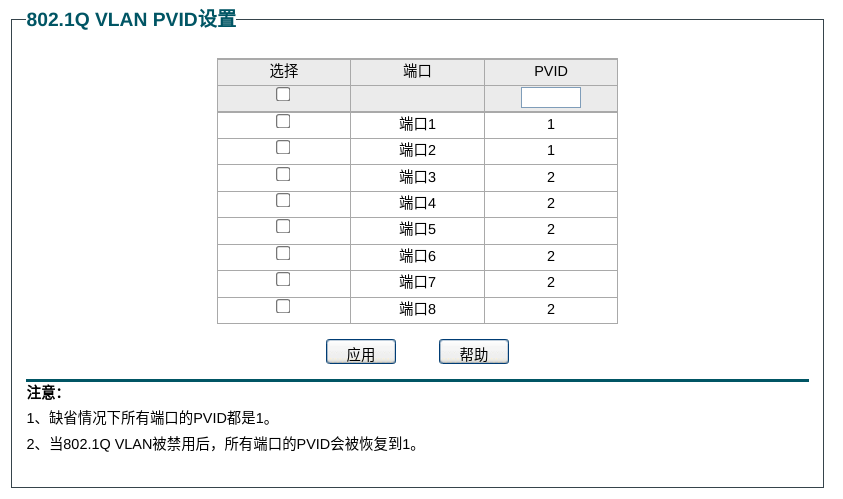
由于树莓派只有一个网口,因此我们需要通过 VLAN 的方式使这个网口同时作为 WAN 口和 LAN 口工作。因此我们划分两个 VLAN:VLAN1 作 WAN,VLAN2 作 LAN。端口 1 接外部网线,端口 2 接树莓派,端口 3-8 接局域网内的设备,配置如下图所示:
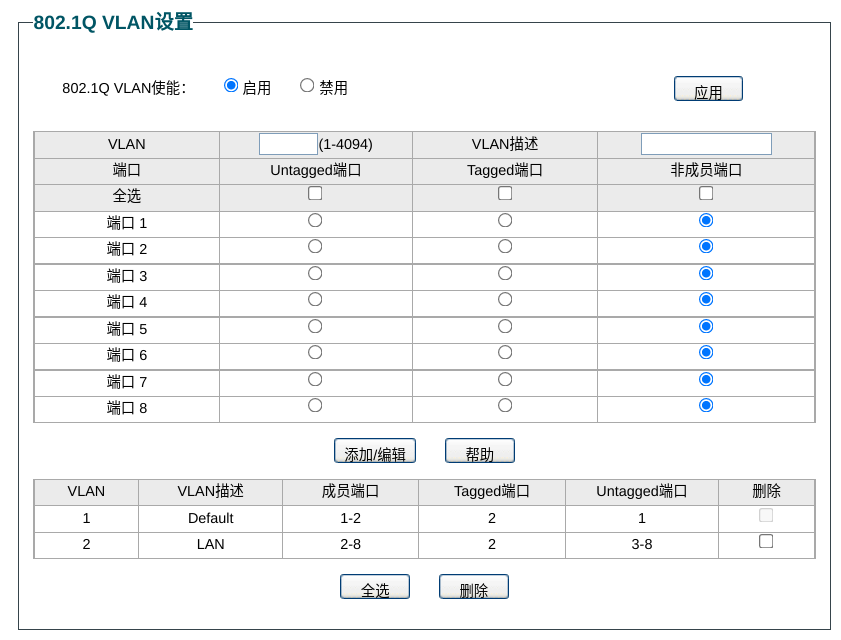
先看 VLAN1。没有 Tag 的外部流量从端口 1 进入,被打上端口1的 PVID=1,发送到 Tagged 的端口 2;端口 2 的流量发出后流向端口 1,由于端口 1 是 Untagged 因此抹除 Tag 发送出去。进出流量都可以正常运转。
再看 VLAN2。端口 2 发出的报文需要带有对应的 VLAN ID,因此端口 2 是 Tagged;其他端口都不需要让网络使用者知道其对应的 VLAN,因此是 Untagged。当流量从端口 3-8 进入时,自动打上 PVID=2,并被发送到端口 2;当流量从端口 2 流出时,同样地会被正常转发到实际的端口。
至此,交换机部分的配置就基本完成了。
安装:树莓派
由于是全新的树莓派,因此需要安装系统。我这里选择的是 ArchLinux ARM,官网对树莓派的安装有详细教程,这里就不展开了。
配置:网络接口
由于划分了两个 VLAN,因此对应的就需要两个 vlan 的网口。同时为了实现 IPv6 的 Passthrough,我们需要将它们桥接在一起。最后形成的配置如下:
eth0
[Match]Name=eth0
[Network]VLAN=eth0.1VLAN=eth0.2从 eth0 分出两个 VLAN 接口,分别为 eth0.1 和 eth0.2。
eth0.1
[NetDev]Name=eth0.1Kind=vlan
[VLAN]Id=1第一个 VLAN 网络设备,VLAN ID=1。
[Match]Name=eth0.1
[Network]Bridge=br-lanAddress=49.140.123.234/24Gateway=49.140.123.254DNS=127.0.0.1eth0.1 的网络配置。可以看到它是桥接入 br-lan 的,并且分配了静态的 IP 地址、网关和 DNS。
eth0.2
[NetDev]Name=eth0.2Kind=vlanMACAddress=2a-62-d5-f6-e8-7f
[VLAN]Id=2第二个网络设备,VLAN ID=2。
这里给它手动分配了一个 MAC 地址,否则 VLAN 设备的 MAC 地址会和其 Parent 设备,即 eth0 保持一致。MAC 地址的配置
MACAddress 支持 : 分隔、- 分隔和点分隔三种形式。注意这个地址必须是有效的,否则端口是起不来的,同时 journalctl -xe 里会有 Failed to set MAC address, ignoring: Cannot assign requested address 的报错。
[Match]Name=eth0.2
[Network]Bridge=br-laneth0.2 的网络配置,相当简单,不需要有网络地址,只作交换用。
br-lan
[NetDev]Name=br-lanKind=bridge网络设备 br-lan,负责桥接起所有的网口。
[Match]Name=br-lan
[Network]IPMasquerade=ipv4
[Address]Address=10.245.0.1/16br-lan 的网络配置,Address 部分填写内网的网段。我这里选用的内网网段是 10.245.0.1/16。
ebtables
将 eth0.1 加入 br-lan 后,局域网内的设备就可以直接获取到 IPv6 的公网地址了。但 IPv4 的访问也因此中断。因此我们需要让 IPv4 不要被桥接出去,走正常的路由;仅 IPv6 桥接就可以了。
由于 nftables 暂时不支持 ebtables 的 broute 表ebtables。但 archlinux-arm 并没有提供对应的包,因此这里就需要我们手动构建了。首先是安装 base-devel:
pacman -S base-devel然后从 AUR 上找到对应的包:https://aur.archlinux.org/packages/ebtables:
git clone https://aur.archlinux.org/ebtables.gitcd ebtables下载完之后需要修改 PKGBUILD,在 arch 中增加 armv7h,然后就可以构建了:
makepkg -si .如此就安装完成了。
我们可以把 ebtables 的配置写成简单的 systemd 服务,如下所示:
[Unit]After=network.targetWants=network.target
[Service]Type=oneshotRemainAfterExit=yesExecStart=/usr/bin/ebtables -t broute -A BROUTING -p ! ipv6 -j DROP -i eth0.1ExecStop=/usr/bin/ebtables -t broute -D BROUTING -p ! ipv6 -j DROP -i eth0.1
[Install]WantedBy=multi-user.target然后运行并开机启动就可以了。
systemctl start route-ipv4systemctl enable route-ipv4效果
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00inet 127.0.0.1/8 scope host lovalid_lft forever preferred_lft foreverinet6 ::1/128 scope hostvalid_lft forever preferred_lft forever2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000link/ether [redacted] brd ff:ff:ff:ff:ff:ffinet6 fe80::[redacted]/64 scope linkvalid_lft forever preferred_lft forever3: br-lan: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000link/ether [redacted] brd ff:ff:ff:ff:ff:ffinet 10.245.0.1/16 brd 10.245.255.255 scope global br-lanvalid_lft forever preferred_lft foreverinet6 2001:[redacted]/64 scope global dynamic mngtmpaddr noprefixroutevalid_lft 2591981sec preferred_lft 604781secinet6 fe80::[redacted]/64 scope linkvalid_lft forever preferred_lft forever4: eth0.1@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-lan state UP group default qlen 1000link/ether [redacted] brd ff:ff:ff:ff:ff:ffinet 49.[redacted]/24 brd 49.[redacted] scope global eth0.1valid_lft forever preferred_lft forever5: eth0.2@eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master br-lan state UP group default qlen 1000link/ether [redacted] brd ff:ff:ff:ff:ff:ff6: wlan0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master br-lan state UP group default qlen 1000link/ether [redacted] brd ff:ff:ff:ff:ff:ffinet6 fe80::[redacted]/64 scope linkvalid_lft forever preferred_lft foreverbr-lan 拥有内网的 IPv4 地址和公网 2001 开头的 IPv6 地址,eth0.1 拥有公网 IPv4 地址。双栈都可以正常访问。
安装:MariaDB
首先是安装:
pacman -S mariadb然后是初始化:
mariadb-install-db --user=mysql --basedir=/usr --datadir=/var/lib/mysql初始化完成后会自动生成两个账户:root 和 mysql。这两个账户都没有密码,但需要登录时是对应的用户才可以正常访问。随后,我们配置一些必要的安全选项:
mysql_secure_installation最后启动即可:
systemctl start mariadbsystemctl enable mariadb配置:DHCP
我们选择通过 kea 配置 DHCP。首先是安装:
pacman -S kea配置数据库(可选)
如果我们想使用 mariadb 替代 memfile,就需要在数据库里新建一张表和一个用户供 kea 使用:
CREATE DATABASE kea;CREATE USER 'kea'@'localhost' IDENTIFIED BY 'kea';GRANT ALL ON kea.* TO 'kea'@'localhost';quit然后通过 kea-admin 初始化:
kea-admin db-init mysql -u kea -p kea -n kea配置文件
然后编辑 kea-dhcp4 的配置文件:
{ "Dhcp4": { "interfaces-config": { // 需要监听的端口是 br-lan "interfaces": ["br-lan"], "dhcp-socket-type": "raw" },
"valid-lifetime": 3600, "renew-timer": 900, "rebind-timer": 1800,
"subnet4": [ { // 分配网段 "subnet": "10.245.0.0/24", // IP 池 "pools": [{ "pool": "10.245.0.2 - 10.245.0.254" }],
"option-data": [ { // 默认网关 "name": "routers", "data": "10.245.0.1" }, { // 默认 DNS "name": "domain-name-servers", "data": "10.245.0.1" } ] } ],
"control-socket": { "socket-type": "unix", "socket-name": "/tmp/kea4-ctrl-socket" },
"lease-database": { "type": "memfile", "lfc-interval": 3600 },
// 如果上面使用了数据库,这里可以取消注释 //"hosts-database": { // "type": "mysql", // "name": "kea", // "user": "kea", // "password": "kea", // "host": "localhost", // "port": 3306 //},
"option-data": [ { "name": "domain-search", "data": "mmf.lan, lan.mmf.moe" } ],
"loggers": [ { "name": "kea-dhcp4", "output_options": [ { "output": "/var/log/kea-dhcp4.log" } ], "severity": "INFO", "debuglevel": 0 } ] }}最后启动服务:
systemctl start kea-dhcp4systemctl enable kea-dhcp4配置:无线网络
我们选用 hostapd,使用树莓派的板载无线网卡开启 AP。首先是安装,直接通过 pacman 安装即可:
pacman -S hostapd配置如下:
interface=wlan0bridge=br-landriver=nl80211own_ip_addr=127.0.0.1ctrl_interface=/run/hostapdctrl_interface_group=0
## 基本信息#ssid=SSID Of Your WiFiwpa_passphrase=Your password
# 国家代码country_code=CN# 信道为 40,5200 MHz,在中国和日本的信道重合范围内channel=40
# IEEE 802.11ahw_mode=aieee80211n=1ht_capab=[HT40+][SHORT-GI-40][DSSS_CCK-40]ieee80211ac=1
## WPA2 认证配置#wpa=2wpa_key_mgmt=WPA-PSKwpa_pairwise=CCMP# 1=WPAauth_algs=1
## 日志#logger_syslog=-1logger_syslog_level=2logger_stdout=-1logger_stdout_level=2
## MAC 地址黑名单#macaddr_acl=0deny_mac_file=/etc/hostapd/hostapd.deny
## WMM 相关配置#wmm_enabled=1wmm_ac_bk_cwmin=4wmm_ac_bk_cwmax=10wmm_ac_bk_aifs=7wmm_ac_bk_txop_limit=0wmm_ac_bk_acm=0wmm_ac_be_aifs=3wmm_ac_be_cwmin=4wmm_ac_be_cwmax=10wmm_ac_be_txop_limit=0wmm_ac_be_acm=0wmm_ac_vi_aifs=2wmm_ac_vi_cwmin=3wmm_ac_vi_cwmax=4wmm_ac_vi_txop_limit=94wmm_ac_vi_acm=0wmm_ac_vo_aifs=2wmm_ac_vo_cwmin=2wmm_ac_vo_cwmax=3wmm_ac_vo_txop_limit=47wmm_ac_vo_acm=0那堆 wmm 相关的配置在安装自带的配置文件里没有注释掉,因此这里我也保留了。这里有个坑点是树莓派的板载网卡不支持 ACS,即自动信道探测。
可以看到,AP 接入的方式是 bridge 进了 br-lan,因此可以直接从 br-lan 的 DHCP 获取到 IPv4 地址;能够直接通过 SLAAC 获取到公网 IPv6。配置完成后直接启动 hostapd 就可以了:
systemctl start hostapdsystemctl enable hostapd配置:透明代理
至此,有线网络和无线网络都可以正常工作了,于是问题就只剩下透明代理了。透明代理的实现有两个最重要的问题:DNS 和代理方式。
DNS 我这里选择的是 chinadns-ng+dnsmasq 的方案。黑白名单的设计与我理想中的 DNS 获取方式完全契合,dnsmasq 则在缓存的同时能够给自定义解析域名,对内网服务的部署是一大助力。
剩下的问题就是代理方式了。我选择的方案是 ipt2socks 配合 v2 的本地 socks5 服务器。选用 ipt2socks 是为了和 v2 的实现解耦,v2 则是简单地作代理用,外加给自己的流量打上 SO_MARK。
另一个相对次要的问题就是 IPv6。IPv6 的透明代理看上去就很奇怪,并且也不是所有的代理服务器都支持 IPv6,因此我这里选择仅透明代理 IPv4。仅透明代理 IPv4 就意味着我们需要尽可能地让应用不走 IPv6,因此我选择在 DNS 上下手,拦截所有的 AAAA 返回,这样就只有 IP 直连的情况下才能使用 IPv6 网络了。
设置了这么多限制,那当初配置 IPv6 网络的意义又在哪里呢?意义当然还是有的。首先是 PT,PT 是直接走 IP 的,因此不会受到 DNS 的影响,可以正常运作,这也就意味着 BT 客户端能够正确获取并上报自己的 IPv6 公网 IP,实现点对点的传输;此外,针对实际需要 IPv6 的服务,我们也可以在 dnsmasq 中指定对应的解析。
chinadns-ng
将仓库 clone 到本地,并通过 make 和 make install 构建安装:
git clone https://github.com/zfl9/chinadns-ngcd chinadns-ngmakesudo make install然后新建一个 systemd 的 service:
[Unit]After=network-online.target
[Service]Type=simpleUser=nobodyCapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_BIND_SERVICEAmbientCapabilities=CAP_NET_ADMIN CAP_NET_BIND_SERVICEExecStart=/usr/local/bin/chinadns-ng -c 10.10.10.10,223.5.5.5 -t 1.0.0.1,8.8.4.4 -g /srv/proxy/chinadns-ng/gfwlist.txt -m /srv/proxy/chinadns-ng/chnlist.txt -N
[Install]WantedBy=multi-user.target这里可以看到我们的命令参数。其中 -c 对应的是国内 DNS 服务器,-t 对应的是国外(可信)DNS 服务器,-g 对应的是黑名单,-m 是白名单,-N 则是不返回 IPv6 的解析结果。
chinadns-ng 还需要用到 ipset,因此需要提前导入:
ipset -R <chnroute.ipsetipset -R <chnroute6.ipset为了能够持久化对应的 ipset,我们需要将 ipset 写入 /etc/ipset.conf,然后启动 ipset.service:
ipset save > /etc/ipset.confsystemctl enable ipset注意这里不要 start 这个 ipset.service,因为对应的 set 已经存在了,start 是必定会失败的。只需要 enable 即可,下次启动时就正常了。
一切部署完毕,启动 chinadns-ng:
systemctl start chinadns-ngsystemctl enable chinadns-ng它会默认监听 127.0.0.1 的 65353 端口。
systemd-resolved
在配置 dnsmasq 之前,我们需要先把搅局的 resolved 解决。编辑 /etc/systemd/resolved.conf:
[Resolve]DNSStubListener=no然后重启 systemd-resolved.service,它就不会监听 127.0.0.53:53 了:
systemctl restart systemd-resolveddnsmasq
解决了 resolved,接下来就是 dnsmasq 了。dnsmasq 的存在是为了实现 DNS 缓存和自定义解析,可以直接通过 pacman 直接安装:
pacman -S dnsmasq安装完后修改配置文件:
# 监听 53 端口port=53
# 禁用 /etc/resolv.confno-resolvno-poll
# 监听内网listen-address=127.0.0.1,10.245.0.1
# 指定额外配置文件夹conf-dir=/etc/dnsmasq.d/然后建立 /etc/dnsmasq.d 目录:
mkdir /etc/dnsmasq.d最后将 chinadns-ng 的服务器写入额外配置:
server=127.0.0.1#65353并启动即可:
systemctl start dnsmasqsystemctl enable dnsmasqv2
这里给出一个最简单的配置,监听的是 127.0.0.1:1080。所有传入流量都会走代理,除了 BT 流量会直连。所有的传出流量都带有值为 0xff 的 SO_MARK。
{ "log": { "loglevel": "error" }, "inbounds": [ { "port": 1080, "listen": "127.0.0.1", "protocol": "socks", "sniffing": { "enabled": true, "destOverride": ["http", "tls"] }, "settings": { "auth": "noauth", "udp": true } } ], "outbounds": [ { "tag": "proxy", "protocol": "vmess", "settings": { "vnext": [ { "address": "your-domain", "port": 443, "users": [ { "id": "your-uuid", "alterId": 64 } ] } ] }, "streamSettings": { "network": "ws", "security": "tls", "wsSettings": { "path": "/your-path" }, "sockopt": { "mark": 255 } } }, { "tag": "direct", "protocol": "freedom", "settings": { "domainStrategy": "UseIP" }, "streamSettings": { "sockopt": { "mark": 255 } } } ], "routing": { "domainStrategy": "IPOnDemand", "rules": [ { "type": "field", "protocol": ["bittorrent"], "outboundTag": "direct" } ] }}ipt2socks
这里就直接参考 KAAAsS 的配置了,详细的解释在对应文章里有说明。
[Unit]Description=utility for converting iptables(redirect/tproxy) to socks5After=network.target
[Service]User=nobodyEnvironmentFile=/usr/local/etc/ipt2socks/ipt2socks.confCapabilityBoundingSet=CAP_NET_ADMIN CAP_NET_BIND_SERVICEAmbientCapabilities=CAP_NET_ADMIN CAP_NET_BIND_SERVICENoNewPrivileges=trueExecStart=/usr/local/bin/ipt2socks -s $server_addr -p $server_port -l $listen_port -j $thread_nums $extra_argsRestart=on-failureRestartSec=5LimitNOFILE=20480
[Install]WantedBy=multi-user.target# ipt2socks configure file## detailed helps could be found at: https://github.com/zfl9/ipt2socks# Socks5 server ipserver_addr=127.0.0.1# Socks5 server portserver_port=1080# Listen port numberlisten_port=60080# Number of the worker threadsthread_nums=1# Extra argumentsextra_args=nftables
最后就是 nftables 的配置了。不过在此之前,还需要执行 iproute 的命令:
ip -4 rule add fwmark 1 table 100ip -4 route add local default dev lo table 100这两条已经是我们的老朋友了,不用多说。下面就是正片:
define lo_fwmark = 1define tproxy_port = 60080define dns_port = 53define direct_fwmark = 0xff
## 新建表#add table proxy
## 国内路由#include "/srv/proxy/config/chnroute.ruleset"
## 私有网段#include "/srv/proxy/config/private.ruleset"
## 代理规则#add chain proxy doproxy# 从 connmark 中恢复 markadd rule proxy doproxy meta mark set ct mark# 避免回环add rule proxy doproxy mark $lo_fwmark return# 私有地址直连add rule proxy doproxy ip daddr @private_addr return# 国内 IP 直连add rule proxy doproxy ip daddr @chnroute counter return# 重路由 TCP(SYN)add rule proxy doproxy tcp flags syn counter meta mark set $lo_fwmark# 重路由 UDPadd rule proxy doproxy meta l4proto udp ct state new counter meta mark set $lo_fwmark# 将 mark 存储到 connmark 中add rule proxy doproxy ct mark set mark
## 局域网代理#add chain proxy prerouting { type filter hook prerouting priority 0 ; }# 放行本地不带 mark 的包add rule proxy prerouting iifname "lo" mark != $lo_fwmark return# 放行非本地发出的 DNS 包,供后续劫持add rule proxy prerouting fib saddr type != local udp dport $dns_port return# 对非本机发出、非本机接收的包进行规则路由add rule proxy prerouting meta l4proto {tcp, udp} fib saddr type != local fib daddr type != local jump doproxy# 对带有 $lo_fwmark 的包 转发至 ipt2socks 端口add rule proxy prerouting meta l4proto {tcp, udp} mark $lo_fwmark tproxy to 127.0.0.1:$tproxy_port meta mark set $lo_fwmark
## 劫持局域网 DNS#add chain proxy dns { type nat hook prerouting priority 0 ; }add rule proxy dns fib saddr type != local udp dport 53 counter redirect to :$dns_port
## 本机代理#add chain proxy output { type route hook output priority 0 ; }# 直连 direct_fwmark 流量add rule proxy output mark $direct_fwmark return# 对本机发出的剩余包进行规则路由add rule proxy output meta l4proto {tcp, udp} fib saddr type local fib daddr type != local jump doproxy这个配置参照了 KAAAsS 的配置以及新白话文教程中对应的 nftables 部分。核心思想和 iptables 版本的一样,都是在 Prerouting 部分下手。对于本机发出的包,首先经过 $direct_fwmark 的判断,放行这部分直连;对于没有 $direct_fwmark 且 saddr 为本地、daddr 不为本地的 TCP、UDP 包执行规则路由(跳转到 doproxy 链)。在 doproxy 链中对需要代理的包会进行一次 mark,使其来到 Prerouting 链。
对局域网的包而言,我们首先放行了本地发出且不带 $lo_fwmark 的包,然后放行了局域网传来的所有 DNS 包(saddr != local 的 udp dport $dns_port 包),接下来对局域网传来的非本机发出、非本机目的地的包进行规则路由,最后将带有 $lo_fwmark 的包送到了 TProxy 的端口。
对规则路由而言,其判断的本质就是 chnroot 和 privateip_addr 两个 set。当 daddr 在这两个 set 中时,是无条件走直连的。此外,为了减少匹配次数,这里前后还使用了 conntrack。meta mark set ct mark 中的 ct 就是 conntrack 的缩写,这句等效于 skb->mark = nf_conn->mark,意思是说给数据包标记上 conntrack 中的 mark。如果这个包是之前连接的一部分,那么在这一步中就能从之前的连接中把 mark 恢复,后面的步骤就不需要对其进行标记了,减少了标记的次数。配合这条规则的是最后的 ct mark set mark,等效 nf_conn->mark = skb->mark,将当前包的 mark 存储到 nf_conn 中供之后复用。打上 mark 的时机也有讲究,是对 flag 含 SYN 的 TCP 包和 state new 的 UDP 包进行。
最后就是拦截局域网 DNS 了。在 Prerouting 里我们选择放行局域网的 DNS 包,而在此之后我们把这个包 redirect 到 :$dns_port,即本地的 DNS 服务,这样就可以确保所有去往 :53 的包都由本机的 dnsmasq 处理了。
上述的规则中引用了两个文件,一个是 chnroute.ruleset,这个文件是通过 chinadns-ng 的 chnroute.ipset 转换过来的,由于原文过长,这里就不贴出来了,内容格式如下:
#!/usr/sbin/nft -f
add set v2ray chnroute { type ipv4_addr; flags interval; }add element v2ray chnroute { 1.0.1.0/24 }add element v2ray chnroute { 1.0.2.0/23 }add element v2ray chnroute { 1.0.8.0/21 }add element v2ray chnroute { 1.0.32.0/19 }add element v2ray chnroute { 1.1.0.0/24 }add element v2ray chnroute { 1.1.2.0/23 }add element v2ray chnroute { 1.1.4.0/22 }然后是 private.ruleset,记录了 IPv4 中的所有私有地址:
#!/usr/sbin/nft -f
add set v2ray private_addr { type ipv4_addr; flags interval; }add element v2ray private_addr { 0.0.0.0/8 }add element v2ray private_addr { 10.0.0.0/8 }add element v2ray private_addr { 100.64.0.0/10 }add element v2ray private_addr { 127.0.0.0/8 }add element v2ray private_addr { 169.254.0.0/16 }add element v2ray private_addr { 172.16.0.0/12 }add element v2ray private_addr { 192.0.0.0/24 }add element v2ray private_addr { 192.0.2.0/24 }add element v2ray private_addr { 192.88.99.0/24 }add element v2ray private_addr { 192.168.0.0/16 }add element v2ray private_addr { 198.18.0.0/15 }add element v2ray private_addr { 198.51.100.0/24 }add element v2ray private_addr { 203.0.113.0/24 }add element v2ray private_addr { 224.0.0.0/4 }add element v2ray private_addr { 240.0.0.0/4 }add element v2ray private_addr { 255.255.255.255/32 }最后,为了能够快捷地开关透明代理,我们将其部署成 systemd 的 service。需要准备的文件如下:
#!/bin/bash
ip -4 rule add fwmark 1 table 100ip -4 route add local default dev lo table 100
/srv/proxy/config/proxy.nft#!/bin/bash
ip -4 rule delete fwmark 1 table 100ip -4 route delete local default dev lo table 100
nft delete table proxy拜 nftables 的配置所赐,在结束的时候我们只需要直接对我们创建的 table 进行一个删除就可以了。
[Unit]Description=iproute2 and nftables rules for transparent proxyPartOf=systemd-networkd.serviceAfter=network.target systemd-networkd.serviceWants=network.target
[Service]Type=oneshotRemainAfterExit=yesExecStart=/srv/proxy/transparent_proxy.shExecStop=/srv/proxy/transparent_proxy_off.sh
[Install]WantedBy=multi-user.target这里需要注意的是 transparent-proxy.service 必须在 systemd-networkd.service 之后启动,并且要跟随 systemd-networkd 一起开启/关闭(PartOf)。配置完后启动即可:
systemctl start transparent-proxysystemctl enable transparent-proxy至此,最后一片拼图也完成了。
结语
终于,我们得到了一个能用的软路由。它可以完美地完成原本由笔记本提供的代理功能,自带的无线网卡虽然表现一般但也能有百兆的速度,一切都正常地运转起来了。
但现在的配置还是有一些令人不大满意的地方,比如:
chinadns-ng使用了ipset,但我们的配置使用了nftables的set,需要维护两份列表chinadns-ng的filter ipv6模式会拦截所有的ipv6,我们希望能够放行国内域名的ipv6解析IPv4路由使用的是ebtables的broute表,该filter目前nftables尚未支持- 现在公网
IPv4在eth0.1上,公网IPv6在br-lan上,显得十分诡异 - 等等……
这些问题或许会在后续的使用中慢慢解决,或许不会(
总之,能用万岁!(笑)
参考
- https://archlinuxarm.org/platforms/armv8/broadcom/raspberry-pi-4
- https://wiki.archlinux.org/title/MariaDB\_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)
- https://github.com/zfl9/chinadns-ng
- https://wiki.archlinux.org/title/Ipset\_(%E7%AE%80%E4%BD%93%E4%B8%AD%E6%96%87)#%E4%BD%BFipset%E6%8C%81%E4%B9%85%E5%8C%96
- https://blog.kaaass.net/archives/1446
- https://github.com/kaaass/manjaro-settings/blob/master/home/kaaass/shell/transparent\_proxy.sh